Credit Card Spend Anomaly Detection
The dataset for credict card spend anomaly is highly skewed (i.e., We have very few positive/fradulent examples in the dataset).
In this tutorial we will build a Dense model with class weighted loss function to fit the skewed data and apply our model to make predictions.
First we import pandas and read in the credit card spend data set
import pandas as pd
raw_data = pd.read_csv("creditcard.csv")
We show the first 5 row of the data set
raw_data.head()
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | ... | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | ... | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | ... | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | ... | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | ... | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
5 rows × 31 columns
We describe basic statistics of all numeric type columns (features)
raw_data.describe()
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | ... | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 284807.000000 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | ... | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 284807.000000 | 284807.000000 |
| mean | 94813.859575 | 1.165980e-15 | 3.416908e-16 | -1.373150e-15 | 2.086869e-15 | 9.604066e-16 | 1.490107e-15 | -5.556467e-16 | 1.177556e-16 | -2.406455e-15 | ... | 1.656562e-16 | -3.444850e-16 | 2.578648e-16 | 4.471968e-15 | 5.340915e-16 | 1.687098e-15 | -3.666453e-16 | -1.220404e-16 | 88.349619 | 0.001727 |
| std | 47488.145955 | 1.958696e+00 | 1.651309e+00 | 1.516255e+00 | 1.415869e+00 | 1.380247e+00 | 1.332271e+00 | 1.237094e+00 | 1.194353e+00 | 1.098632e+00 | ... | 7.345240e-01 | 7.257016e-01 | 6.244603e-01 | 6.056471e-01 | 5.212781e-01 | 4.822270e-01 | 4.036325e-01 | 3.300833e-01 | 250.120109 | 0.041527 |
| min | 0.000000 | -5.640751e+01 | -7.271573e+01 | -4.832559e+01 | -5.683171e+00 | -1.137433e+02 | -2.616051e+01 | -4.355724e+01 | -7.321672e+01 | -1.343407e+01 | ... | -3.483038e+01 | -1.093314e+01 | -4.480774e+01 | -2.836627e+00 | -1.029540e+01 | -2.604551e+00 | -2.256568e+01 | -1.543008e+01 | 0.000000 | 0.000000 |
| 25% | 54201.500000 | -9.203734e-01 | -5.985499e-01 | -8.903648e-01 | -8.486401e-01 | -6.915971e-01 | -7.682956e-01 | -5.540759e-01 | -2.086297e-01 | -6.430976e-01 | ... | -2.283949e-01 | -5.423504e-01 | -1.618463e-01 | -3.545861e-01 | -3.171451e-01 | -3.269839e-01 | -7.083953e-02 | -5.295979e-02 | 5.600000 | 0.000000 |
| 50% | 84692.000000 | 1.810880e-02 | 6.548556e-02 | 1.798463e-01 | -1.984653e-02 | -5.433583e-02 | -2.741871e-01 | 4.010308e-02 | 2.235804e-02 | -5.142873e-02 | ... | -2.945017e-02 | 6.781943e-03 | -1.119293e-02 | 4.097606e-02 | 1.659350e-02 | -5.213911e-02 | 1.342146e-03 | 1.124383e-02 | 22.000000 | 0.000000 |
| 75% | 139320.500000 | 1.315642e+00 | 8.037239e-01 | 1.027196e+00 | 7.433413e-01 | 6.119264e-01 | 3.985649e-01 | 5.704361e-01 | 3.273459e-01 | 5.971390e-01 | ... | 1.863772e-01 | 5.285536e-01 | 1.476421e-01 | 4.395266e-01 | 3.507156e-01 | 2.409522e-01 | 9.104512e-02 | 7.827995e-02 | 77.165000 | 0.000000 |
| max | 172792.000000 | 2.454930e+00 | 2.205773e+01 | 9.382558e+00 | 1.687534e+01 | 3.480167e+01 | 7.330163e+01 | 1.205895e+02 | 2.000721e+01 | 1.559499e+01 | ... | 2.720284e+01 | 1.050309e+01 | 2.252841e+01 | 4.584549e+00 | 7.519589e+00 | 3.517346e+00 | 3.161220e+01 | 3.384781e+01 | 25691.160000 | 1.000000 |
8 rows × 31 columns
Get feature matrix and labels
labels = raw_data["Class"].astype('category')
featureMatrix = raw_data.loc[:,(raw_data.columns != 'Time') & (raw_data.columns != 'Class')]
We plot the distribution of the labels and the label is highly skewed, with much more negative data than positive.
import matplotlib.pyplot as plt
%matplotlib inline
count_classes = pd.value_counts(labels)
count_classes.plot(kind='bar')
plt.ylabel("Frequency")
ax = plt.gca()
ax.set_yscale('log')
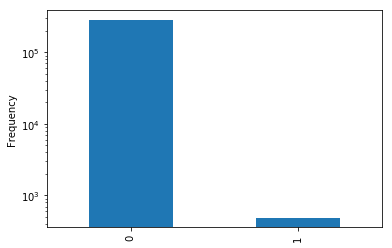
We import sklearn module to split the data into train and test subsets and calculate the class weights to be used for class weighted loss function.
from sklearn.model_selection import train_test_split
from sklearn.utils import class_weight
import numpy as np
x_train, x_test, y_train, y_test = train_test_split(featureMatrix, labels, test_size = 0.1, stratify=labels)
x_train = x_train.as_matrix()
x_test = x_test.as_matrix()
y_train = y_train.as_matrix()
y_test = y_test.as_matrix()
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
class_weights = class_weight.compute_class_weight('balanced',np.unique(y_train), y_train)
print(class_weights)
(256326, 29) (28481, 29) (256326,) (28481,)
[ 0.50086563 289.30699774]
/usr/local/lib/python3.7/site-packages/ipykernel_launcher.py:5: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
"""
/usr/local/lib/python3.7/site-packages/ipykernel_launcher.py:6: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
/usr/local/lib/python3.7/site-packages/ipykernel_launcher.py:7: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
import sys
/usr/local/lib/python3.7/site-packages/ipykernel_launcher.py:8: FutureWarning: Method .as_matrix will be removed in a future version. Use .values instead.
Using Keras API, we build a simple Sequential model with 3 Dense layers and sigmoid activation in the output layer.
from keras.layers import Dense, BatchNormalization, Dropout
from keras.models import Sequential
mySimpleModel = Sequential()
mySimpleModel.add(BatchNormalization(input_shape=(29,)))
mySimpleModel.add(Dense(60))
mySimpleModel.add(Dropout(0.8))
mySimpleModel.add(BatchNormalization())
mySimpleModel.add(Dense(30))
mySimpleModel.add(Dropout(0.8))
mySimpleModel.add(BatchNormalization())
mySimpleModel.add(Dense(1,activation='sigmoid'))
mySimpleModel.compile(loss='binary_crossentropy', optimizer = 'adam', metrics=['accuracy'])
mySimpleModel.summary()
Using TensorFlow backend.
WARNING:tensorflow:From /usr/local/lib/python3.7/site-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /usr/local/lib/python3.7/site-packages/keras/backend/tensorflow_backend.py:3445: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
batch_normalization_1 (Batch (None, 29) 116
_________________________________________________________________
dense_1 (Dense) (None, 60) 1800
_________________________________________________________________
dropout_1 (Dropout) (None, 60) 0
_________________________________________________________________
batch_normalization_2 (Batch (None, 60) 240
_________________________________________________________________
dense_2 (Dense) (None, 30) 1830
_________________________________________________________________
dropout_2 (Dropout) (None, 30) 0
_________________________________________________________________
batch_normalization_3 (Batch (None, 30) 120
_________________________________________________________________
dense_3 (Dense) (None, 1) 31
=================================================================
Total params: 4,137
Trainable params: 3,899
Non-trainable params: 238
_________________________________________________________________
We fit the model to get parameters
mySimpleModel.fit(x_train, y_train, epochs=1, verbose=1, class_weight=class_weights)
WARNING:tensorflow:From /usr/local/lib/python3.7/site-packages/tensorflow/python/ops/math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Epoch 1/1
256326/256326 [==============================] - 25s 99us/step - loss: 0.0284 - acc: 0.9908
<keras.callbacks.History at 0x11446d860>
We predict the label based on test data and print out the positive predictions.
y_pred = mySimpleModel.predict(x_test)
ydisplay = y_pred[y_pred > 0.5]
ydisplay
array([1. , 1. , 1. , 0.99870545, 1. ,
1. , 0.9999956 , 1. , 0.99976003, 1. ,
1. , 0.9997549 , 1. , 1. , 1. ,
0.9998375 , 1. , 0.9999987 , 0.9999997 , 1. ,
0.99999976, 0.9999989 , 0.9999906 , 1. , 1. ,
1. , 1. , 1. , 1. , 1. ,
1. , 1. , 0.997558 , 1. , 1. ,
0.9999993 , 1. , 0.99999976, 0.9999987 , 1. ,
0.99998754, 1. , 1. , 1. , 1. ],
dtype=float32)
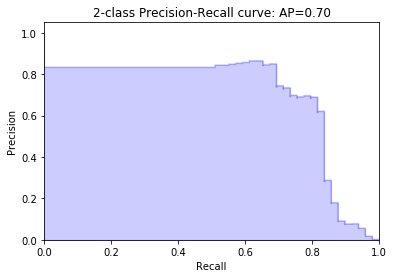
We calculate the average precision-recall score.
from sklearn.metrics import average_precision_score
average_precision = average_precision_score(y_test, y_pred)
print('Average precision-recall score: {0:0.2f}'.format(
average_precision))
Average precision-recall score: 0.70
Precision-Recall curve
from sklearn.metrics import precision_recall_curve
from sklearn.utils.fixes import signature
precision, recall, _ = precision_recall_curve(y_test, y_pred)
# In matplotlib < 1.5, plt.fill_between does not have a 'step' argument
step_kwargs = ({'step': 'post'}
if 'step' in signature(plt.fill_between).parameters
else {})
plt.step(recall, precision, color='b', alpha=0.2,
where='post')
plt.fill_between(recall, precision, alpha=0.2, color='b', **step_kwargs)
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.ylim([0.0, 1.05])
plt.xlim([0.0, 1.0])
plt.title('2-class Precision-Recall curve: AP={0:0.2f}'.format(
average_precision))
Text(0.5, 1.0, '2-class Precision-Recall curve: AP=0.70')
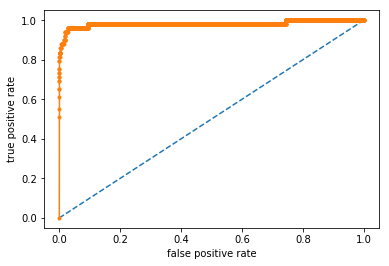
ROC curve
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_test, y_pred)
# plot no skill
plt.plot([0, 1], [0, 1], linestyle='--')
# plot the roc curve for the model
plt.plot(fpr, tpr, marker='.')
plt.xlabel('false positive rate')
plt.ylabel('true positive rate')
# show the plot
plt.show()